MEMBANGUN ALGORITMA PARALEL
Pengertian Algoritma Paralel
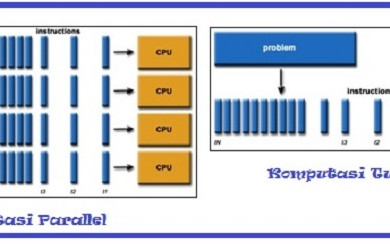
Algoritma paralel merupakan algoritma yang dapat dieksekusi dalam satu waktu pada banyak perangkat processing yang berbeda, algoritma program harus dipecah menjadi beberapa lajur (thread) yang bisa dikerjakan secara bersamaan, masing-masing lajur akan dikerjakan oleh satu core prosesor, dan nanti hasil akhirnya dikumpulkan kembali untuk mendapatkan hasil yang diinginkan.
Platform Algoritma Paralel
Message Passing Interface (MPI)
MPI yaitu suatu standard dan message passing interface partabel system yang didesain oleh grup penelitian dari akademi dan industry untuk mengembangkan fungsi dan macam-macam dari computer parallel. Standar ini mendifinisikan sintaks dan semantic dari core library routine yang berguna untuk memperbesar jangkauan kepada user menulis portable program message passing pada Fortran 77 dan bahasa C, implementasi efisien dari MPI.
Compute Unified Device Architecture (CUDA)
CUDA merupakan platform parallel computing dan model pemrograman yang telah dibuat oleh NVIDIA dan diimplementasikan oleh Graphic Processing Unit (GPU). CUDA memberikan akses pengembangan untuk kumpulan visual instruction dan ingatan dari parallel computasional elemen CUDA GPU.
OpenACC
OpenACC (for Open Accelerators) adalah teknik pemrograman yang dirancang untuk mengoptimalkan komputasi paralel pada sistem komputer heterogen (CPU+GPU), OpenACC menggunakan bahasa pemrograman C, C++ dan fortran seperti platform algoritma paralel lainnya. Untuk mempercepat proses komputasi OpenACC sangat optimal digunakan dengan GPU NVIDIA.
Membangun Algoritma Paralel

Workflow diatas menjelaskan langkah ? langkah bagaimana membuat algoritma paralel secara umum.
Keunggulan algoritma paralel :
# Waktu eksekusi yang cepat untuk masalah numerik.
# Memaksimalkan kinerja seluruh core dan thread pada sistem komputer.
# Sangat cocok diimplementasikan untuk sistem komputer multicore atau multiprosessor.
# Melakukan riset dengan kebutuhan khusus, dalam hal ini sains dan matematika.